

Googleインデックスのプロセスとは

※本記事は、2019年公開当時の情報を基にした記事です。
2019年1月にGoogle Search Consoleの新バージョンが全ユーザーに開放されました。機能も継続的にアップデートされ、多くの方が活用されていると思います。 新しくなったGoogle Search Consoleは「インデックスカバレッジレポート」や「URL検査ツール」などによって、SEO上の異常検知・全体把握・問題特定を行うことが以前と比べて格段に楽になっています。
これからGoogle Search Consoleを触ろうという人は、まず前提として「Google botがURLを発見する→ページ情報を取得する→ページ情報をインデックス登録する」という流れを理解しておくことが大切です。この記事が皆さんがGoogleインデックスのプロセスを理解する一助になれば幸いです。
「さらにSEOを学びたい!」という方へ
「ナイルのSEO相談室」は業界歴15年超のナイルが運営しているメディアです。SEOの最新情報を随時発信しているので、ぜひブックマークしてください!
またSEOにお悩みの方は無料相談やSEOコンサルティングサービスのご利用もぜひご検討ください!
目次
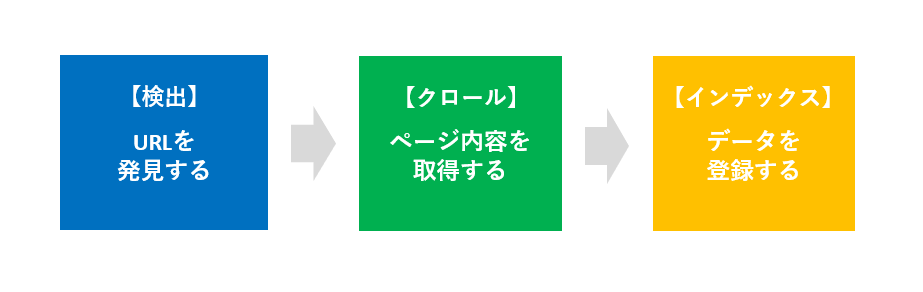
「検出」「クロール」「インデックス」基本のプロセスは3つ
Googleの基本のプロセスは大きく「検出」「クロール」「インデックス」の3つのプロセスに分かれます。(もう少し分けないと問題特定できないので、後ほど説明します。)
参考ページ:Google 検索の仕組み | クロールとインデックス登録
Googleの基本思想は、ユーザーが検索している様々なキーワード(検索クエリ)に対して、即座に適切な情報を検索結果上に返すことです。
そのため、Googlebotは情報を収集するWebページのURLの収集を行っています。収集したURLがどのようなページであるか把握するためにページ情報の取得を行い、その後取得した情報をGoogleのサーバーに保管(インデックス登録)を行います。ここまでが、Googlebotが情報を収集し保管するまでのインデックスの仕組みになります。
検索結果のランキングに表示されるプロセスはまた別のプロセスです。ユーザーが検索を行ったタイミングで、ユーザーが探している情報に適しているデータをインデックスデータの中から検索結果のランキングとしてユーザーに提示しています。インデックスとランキング(アルゴリズム)は別のプロセスになり、今回は前者のインデックスの仕組みに焦点をあてています。
Google Search Consoleを参考にインデックスのプロセスを理解する
新しいGoogle Search Consoleを触っていると、サイト運営者がGooglebotのインデックスプロセスの改善を手助けできるように作られていることが分かります。
ツール内の機能「URL検査ツール」と「インデックスカバレッジレポート」を確認すると、インデックスの一連のプロセスでGooglebotが認識をしている内容を把握することが出来ます。特に、「URL検査ツール」は上記の一連のプロセス通りに「検出」「クロール」「インデックス作成」と項目が分かれており、各項目でGoogleが認識している状況のデータを提供しています。
それらの機能を元に確認できる項目からGoogleが行っている3つのプロセスを細分化し、整理したものが下記になります。
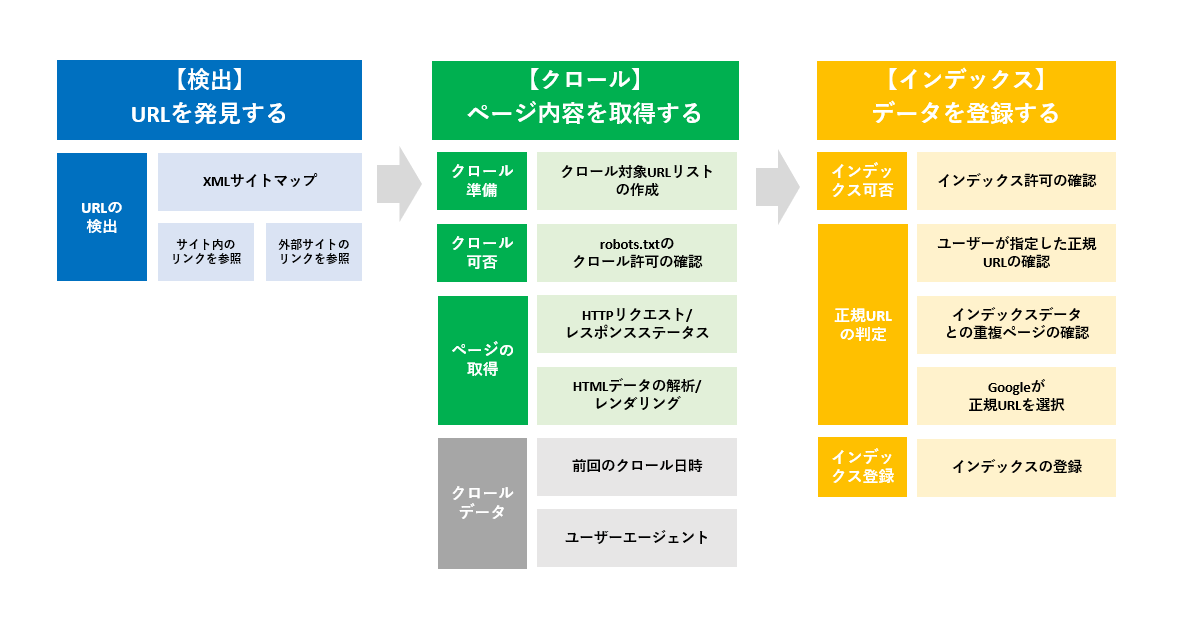
※インデックス作成プロセスは明確に処理の時系列が公表されているわけではないので、推測の部分もあります。(もし間違いがあれば、ご指摘お願いします。)
これより各プロセスにおいてGoogleがどのような処理を行っているのかそれぞれの項目を紹介していきます。JavaScriptの処理などGoogle Search Consoleの機能とは少し外れますがインデックスのプロセスで必ず抑えておきたい情報を補填しています。
1.【検出】URLを発見する
Googleは、URLを発見するために大きく3つの情報を元に行っています。
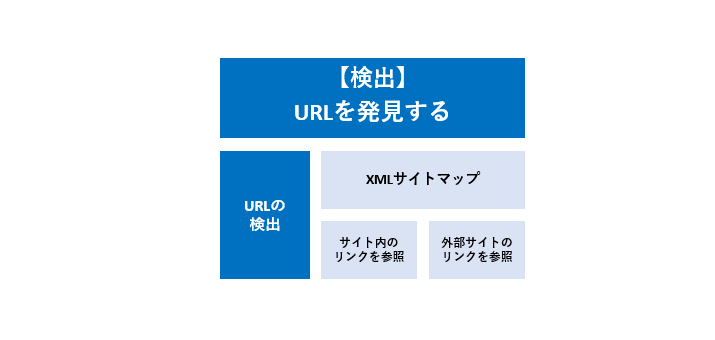
1.1 URLの発見
-
1.1.1 XMLサイトマップ
GoogleはXMLサイトマップに登録されているURLを、クロールを行う手がかりとしているため、サイトの所有者はクロールが行われたいURLを必ずXMLサイトマップに登録を行いましょう。Googleが認識しているXMLサイトマップに登録されているURLはインデックスカバッレジレポートやURL検査ツールで確認することが出来ます。
Googleが公言しているわけではありませんが、個人的には、XMLサイトマップに登録されているURLは、登録されていないURLに比べてクロールの優先度は高いと感じます。特に大規模サイトでは、Googlebotのリソースを考える必要が出てくるため、XMLサイトマップのURLリストの更新をコンスタントに行う必要があります。
- 1.1.2 サイト内のリンク
サイト内の内部リンクも手掛かりにしています。Googlebotはページ内容を取得する際に、HTMLを解析し、ページ内に設置されたリンクからクロールを行うURLを発見します。URL検査ツールの「参照元URL」では、URL単位でGoogleが参照した可能性があるURLを確認することが出来ます。XMLサイトマップのみを発見の手がかりとしている場合、参照元ページはなしと表示されます。
リンク切れや正規のURLでないページへのリンク先が設定されていると、Googleはリンク情報を元にリンク先のページを検出し、最悪不要なページがインデックス登録されてしまう恐れがあります。
- 1.1.3 外部サイトのリンク
サイト内部からのリンクと同様に、外部サイトのページがクロールされた際に、リンクも参照してURLの発見を行います。こちらもURL検査ツールで確認できますが、多くの結果を見ていますがサイト内のリンクよりも参照リンクとして表示される数はかなり低い確率であると感じます。
また、Google Search Consoleの他の機能であるリンクレポートからは、サイト全体の参照元URLリストを確認することが出来ます。ただし、URL単位で参照元URLを確認することはできません。
参考ページ:Google Search Console リンクレポートページ
補足:インデックス登録をリクエストする
URL検査ツールでは、サイト所有者がインデックス登録をリクエストすることが可能です。旧Google Search ConsoleのFetch as Googleの機能になります。Googleに発見されていないページでも、インデックス登録が可能であれば、クロール・インデックス登録をGoogleに促すことが可能です。
最近だとXMLサイトマップに登録さえ行っておけば、正常であればGooglebotがクロールは確実にしてもらえるので、昔よりインデックスのリクエストを使用する頻度は下がってきました。大規模サイトだと、URLの数が多すぎるため手動で1URLずつリクエストを送ることは現実的ではないので、インデックスして欲しいURLはXMLサイトマップで管理するのがベストだと考えます。
2.【クロール】ページ内容を取得する
クロールのプロセスでは、「クロールの準備」「クロール許可の確認」「ページの取得」までを行っています。特に「ページの取得」では、サーバサイドやフロントサイドでのSEOの課題が発生しやすいです。
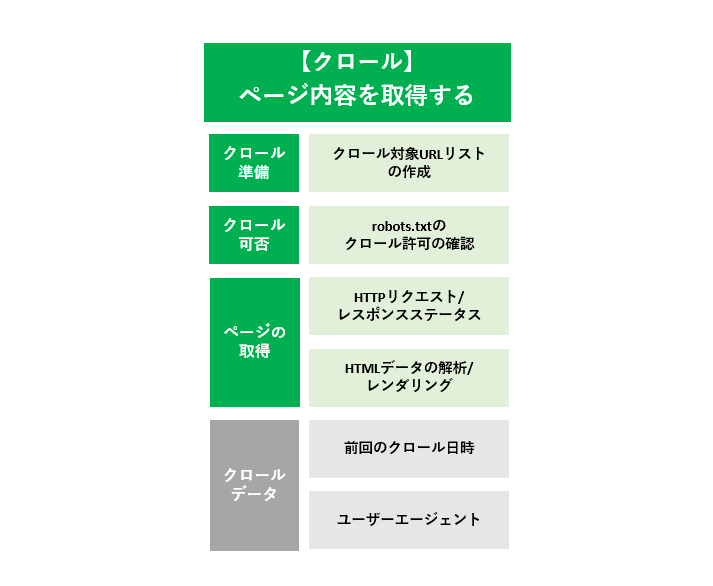
2.1 クロールの準備
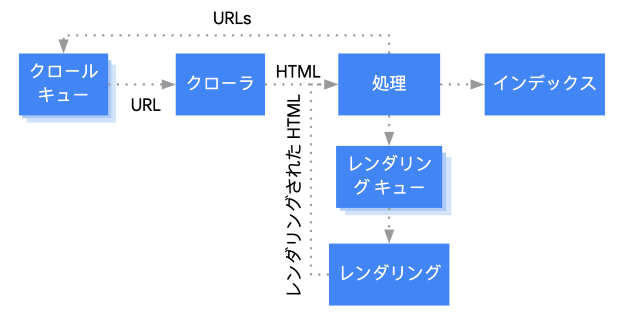
URLが発見された後、Googleはクロール対象のURLを"クロールキュー"に追加します。クロールキューはクロールが行われる前の"クロール待ちURLリスト"になります。Googlebotはクロールキューから"優先度が高いURL"を取得し、クロールを試みます。
Googlebotがクロールできるリソースには限りがある(クロールバジェットという)ため、大規模サイトではURL単位でクロールの優先度を考慮する必要があります。Googlebotのクロールリソースはサイトによってある程度割り当てられており、そのリソースの範囲で優先度が高いページからクロールを行っています。
そのため、必要に応じてサイト全体のクロール対象URLの調整や、URLごとのクロール優先度の管理が必要になってきます。クロールバジェットについては、過去にウェブマスター向け公式ブログで説明されているので、気になる方はこちらの記事をご確認ください。
参考ページ:Google ウェブマスター向け公式ブログ: Googlebot のクロール バジェットとは
2.2 クロール許可の確認
GooglebotはクロールキューからURLを取得すると、サイト運営者が設定しているrobots.txtを元に、対象のURLがGooglebotのクロールを許可されているか確認します。
robots.txtにdisallowで指定されたURLがある場合、Googleは基本的にはそのURLへクロールを行いません。ただし、disallowをしていても、外部リンクによって対象のページを検出し、場合によってはインデックス登録されることがあります。
サイトに robots.txt プロトコルを使用すると、Google のクロールをブロックできますが、必ずしもインデックスに登録されないわけではありません。たとえば、他のサイトからリンクを介して検出されたページはインデックスに登録される可能性があります。
検索結果には表示はされたくないページであれば、disallowでは完璧ではないために、インデックスを許可しない指示のnoindexタグをページに設定することをお奨めします。
2.3 ページの取得
ページの取得の処理では、「サーバーのレスポンスステータスの取得」「ページ内容のデータの取得を行いHTMLの解析・レンダリング」の2つのプロセスに分けることが出来ます。
「レスポンスステータスの取得」ではGooglebotがURLへクロールが出来ているか、「HTMLの解析・レンダリング」ではGooglebotがページコンテンツをどのように認識しているかをプロセスに分けて確認します。
- 2.3.1 HTTPリクエスト/レスポンスステータスの取得
Googlebotはクロールを行う際、HTTPリクエストをWebサーバに送りサーバからのレスポンスステータスコードを受け取ります。Google Search ConsoleではURL単位でGooglebotが受け取っているステータスコードを確認することができ、Googlebotがそもそもページ(URL)にクロールが出来ているかを確認することが出来ます。
Google Search ConsoleでGoogleが認識しているレスポンスステータスコードを確認することは、ページへクロールが試し見られているか、サーバで問題が発生しているのか、その後のプロセスで問題が発生しているのか、を判断することが出来ます。
サーバとクライアントの関係を、初めて聞いたという方は下記の記事を読み理解を深めてましょう。
- 2.3.2 HTMLデータの解析 / レンダリング
Googlebotが正常なレスポンスステータスを受け取った際に、受け取ったHTMLの解析を開始します。また、通常のユーザーがアクセスした際のブラウザの処理と同様にHTMLデータを構築し、実際にユーザーのデバイスでの表示画面を確認するためにHTML・CSSを構築し画面を確認します。ページにクロールが発生しているうえで、Googlebotがページ(URL)のコンテンツを解析出来ているかを確認することが出来ます。
URLにはクロールされているのですが、コンテンツ内容が正常にGoogleに認識されていないことも以前は良く発生していました。Googleが認識しているHTMLソースやレンダリング内容はURL検査ツールで確認することが出来ます。
ここではHTMLの解析・レンダリングについて詳細なプロセスについて割愛していますが、もっと詳しく知りたい方はGoogle Developersの「クリティカル レンダリング パス」のを読むとよいでしょう。
参考ページ:クリティカル レンダリング パス | Web | Google Developers
JavaScriptなどを用いない静的なHTML でページのコンテンツが構成されているのであれば、インデックス作成のプロセスに移ります。ただし、JavaScriptを用いてページのコンテンツを表示させている場合は注意が必要です。
-
補足:JavaScriptのレンダリング処理は静的なHTMLデータとは別プロセス
GooglebotのJavaScriptの処理において、ページがインデックスがされない、コンテンツが認識されない、負荷が掛かりすぎているなど、ページのコンテンツを認識できているのかという問題は昔からSEOに付きまとう問題で、Googlebotがサイトで使用しているJavaScriptをサポートしているかどうかという問題です。今年の5月にJavaScriptのレンダリングエンジンが更新され、Chrome 74相当(以前はChrome 41相当)の最新のJavaScript技術をサポートできるようになり、JavaScriptの処理の範囲が広がりましたが、すべてをサポートできているわけではありません。
また、JavaScriptのレンダリングのプロセスは、静的なHTMLとは別に実行されます。
理由としてはJavaScriptを実行するのに大きなリソースが必要となるためです。HTMLコンテンツの処理時にインデックス登録が許可されているページであれば、一度"レンダリングキュー"で管理され、Googlebotのリソースがあれば順次JavaScriptのレンダリングが行われ、インデックス登録が行われます。
参考ページ:JavaScript SEO の基本を理解する | 検索 | Google Developers
Google Search ConsoleのURL検査ツールを用いて、レンダリングしているデータを確認することが出来ます。検査ツールのバージョンは常にGooglebotと同様のバージョンにアップデートされ続けるとのことです。URL検査ツールでの結果はGooglebotと同じレンダリングシステムという認識で問題ないでしょう。
参考ページ:Official Google Webmaster Central Blog [EN]: Googlebot evergreen rendering in our testing tools
3.【インデックスの作成】取得したページ情報のインデックス登録
インデックスの作成プロセスでは、Googleは取得したページのデータをインデックス登録するべきかの判断を行っています。
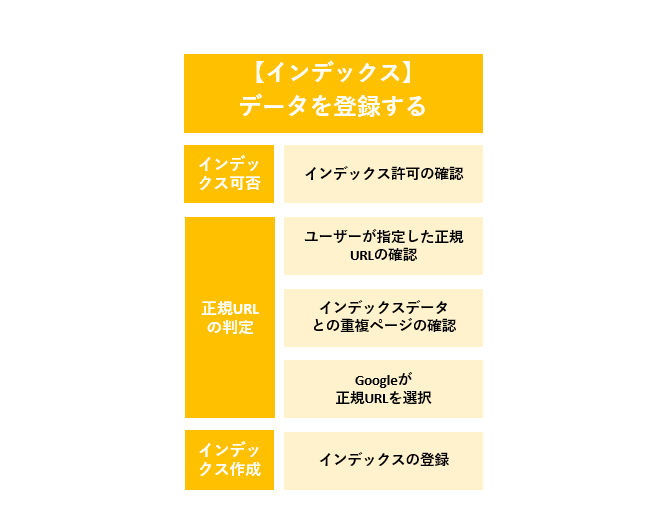
3.1 インデックス登録許可の確認
Googleは、対象URLにnoindexタグのシグナルがあるかHTMLデータを解析する際に確認し、サイト所有者がインデックスを許可しているかを判断します。
インデックス許可をしないことをGoogleに指示する場合、HTMLでのrobotsメタタグやHTTPヘッダーでのX-Robots-Tagで設定できます。
3.2 正規URLの判断
Googleのインデックス作成の判断は、複数の要素を元に判断し、検査対象のURLをインデックス登録するべきかを判断しています。
- 3.2.1 ユーザーが指定した正規URLを確認
Googleは、canonicalやリダイレクト処理でサイト運営者側が指定している正規URLを確認します。Googleはその情報を読み取り、インデックス登録を行う判断の一要素とします。
ここで一要素と記している理由は、Googleはユーザーが指定した正規URLを参考にしますが、その他のシグナルも確認し、最終的に別のURLを正規URLとして判断することがあります。
- 3.2.2 インデックスデータから重複ページを確認
Googleはインデックスデータに重複ページが存在していないかを確認します。重複ページと判断されたURLは、インデックス作成から除外されGoogleが自動で正規のURLを判断します。インデックスカバレッジレポートで重複しているというステータスで検出されます。
- 3.2.3 Googleが正規URLを判断
上記のプロセスを元にGoogleが自動で正規URLの選択を行います。検査対象のURLとは別のURLが正規URLと判断された場合は、インデックスカバッレジレポートで「除外」のステータスで検出されます。
サイト運営者が意図した正規URLがGoogleに選択されなかった場合、異なるページがなぜ重複と判断されてしまっているのか、ユーザーが指定しているURLがなぜ無視されているのかを考える必要があります。
3.3 インデックスの作成
上記の「インデックス登録可否の確認」「ユーザーが指定している正規URLの確認」「Googleが重複ページを確認」「Googleが正規URLを判断」し、ページのインデックスの作成(登録)が行われます。
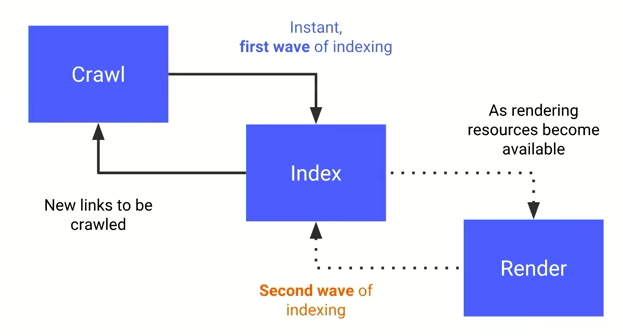
補足:JavaScriptのインデックス処理も少し時間がかかる
JavaScriptのレンダリングは静的なHTMLとは別プロセスで行われるため、データのインデックスも静的なHTMLデータとは別のタイミングで行われます。静的なHTMLのみ先にFirst waveとして先にインデックス登録が行われ、JavaScriptのレンダリングデータはSecond waveでインデックスされます。新しいページをリリースした際などに確認する際は、JavaScript によって生成されるコンテンツのインデックスは、静的なHTMLのインデックスとタイムラグがある点に気を付けてください。
参考ページ:JavaScriptによるnoindex挿入をGoogleは推奨せず、JSレンダリングはセカンドウェーブのインデックス | 海外SEO情報ブログ
インデックスプロセスを理解して、Google Search Consoleを使いこなそう
大規模な不動産サイト・求人サイト・モール型のECサイトのようなシステムで制御しているページが大半のサイトでは、表面上では把握することが出来ないSEO上の問題が少なからず発生してしまいます。
そのような事態が起きた際は、Googleが行っているインデックスプロセスを細分化してGoogle Search ConsoleでGooglebotの処理を確認することで、発生箇所や問題の原因を把握することに繋がります。
今回はGogole Search Consoleでの確認方法などは割愛させていただきましたが、Google Search Consoleではサイトのどこに問題が起きているのか本当に把握しやすくなりました。
この記事を読んでいただき、インデックスのプロセスを把握し、Google Search Consoleを使いこなせる方が一人でも増える手助けになれば嬉しいです。
\プロのノウハウを詰め込みました!資料ダウンロードはこちらから/





PIVOTにもスポンサード出演しました!

動画内では、マーケティング組織立ち上げのための新しい手段についてお話しています。
マーケティング組織に課題がある方はぜひご覧下さい。
動画を見る
関連記事









