

構造化データとは?非エンジニアでもよく分かる!初心者向け徹底解説!
構造化データとは、検索エンジンがページ内容を理解しやすくなるデータ形式のことです。正しく記述することで検索エンジンがページの内容をより理解できるようになります。構造化データの種類によっては検索結果のリッチ化(リッチリザルト)につながるものもあります。
ここでは、初心者でも分かりやすいように構造化データの概要やHTMLでの記述方法、テストツールなどの基本情報を紹介します。
※この記事は2014年に書かれたものを2021年最新版にコンサルタント青木が変更・追記いたしました。
この記事のポイント
- 構造化データとは、検索エンジンがページの内容を理解しやすくなるデータ形式のこと
- 構造化データの種類によっては、使用することで検索結果に画像やレビュー評価などのリッチリザルトが表示される場合がある
- なんでもかんでも構造化データを付与できるわけではないので、サイトのタイプに合わせて適切に使用することが大切
- テストツールを用いて正しく構造化データが記述できているかをチェックすることがポイント
※「内容や仕組みはいいので、運用しているサイトに導入できるか知りたい」「どんな効果があるのか直接聞いてみたい」という方は、お気軽に以下のバナーをクリックしてご相談くださいませ。
目次
これだけは押さえてほしい構造化データ2つのポイント
難しいイメージのある構造化データですが、ざっくりまとめるとこの2つがポイントになります。
- 検索エンジンがページの内容を理解しやすくなる
- 検索結果に様々な要素が表示されるようになる(場合がある)
検索エンジンは人間と同じようにサイトのテキストを理解することができません。もちろんある程度はわかるはずなのですが、完璧とはいきません。そこで、テキストに”意味”のマークアップを行い、検索エンジンがテキストを理解できるようにするというのが、構造化データの基本的な考えになります。
そして、検索エンジンがテキストを理解できるようになると、その情報を使って検索結果に様々な要素を表示できるようになるのです。例えば、「コンビニ アルバイト」などで表示されるGoogleしごと検索(Google for jobs)も構造化データを参考にして、検索結果に表示しています。
なんとなく、構造化データを理解していただけましたでしょうか?ここからはしっかりと構造化データについて解説しますが、困ったら2つのポイントに立ち返ってみてください。
検索エンジンの仕組みやSEOの基本知識については、以下の記事で詳しく解説しております。

セマンティックWebとは
構造化データとセマンティックWebという考え方は切っても切り離せないものです。今回は構造化データを説明する前にセマンティックWebというものに簡単に触れておきたいと思います。
「セマンティックWeb」は、例えば以下のように説明されています。
Webページおよびその中に記述された内容について、それが何を意味するかを表す情報(メタデータ)を一定の規則に従って付加することで、コンピュータが効率よく情報を収集・解釈できるようにする構想。インターネットを単なるデータの集合から知識のデータベースに進化させようという試みがセマンティックWebである。
引用元:セマンティックWeb(Semantic Web)とは
コンピュータ(検索エンジン)は従来、テキストを単なる"文字"として認識し情報として蓄積していました。しかし、それでは検索エンジンは文字を記号としてしか認識することができず、その意味を推し量ることはできません。
そこで、文字を"意味"としてその背景や文脈まで解釈し、それを蓄積していこうというのがセマンティックWebの考え方です。
構造化データとは
つながってきましたでしょうか?そうですセマンティックWebを実現するための手段として、構造化データがあるのです。構造化データは、テキストなどに意味をメタデータとして持たせることで、ロボットが内容の解釈を容易にし、検索エンジンはより有用な検索結果をユーザーに提供できるようになります。
とはいっても、わかりづらいので例を。例えば、以下のような例を考えます。
<div> 名前:青木 創平 生年月日:1994年8月19日 </div>
私達はこれを見た時に、この人は青木創平という"名前"の人物で、1994年の8月19日が"生年月日"だと、ある程度推測することができます。
検索エンジンもその推測ができないわけではありませんが、これを明確に名前と誕生日だと定義することは難しいのです。そこで、"名前"や"生年月日"という情報の「意味」を検索エンジン等に明確に伝えてあげましょうというのが構造化データの考え方です。
構造化データはHTMLに直接マークアップする、もしくはデータハイライターや構造化データ マークアップ支援ツールを用いて設定しますが(設定方法は後述します。)、上述した青木創平の例でいうと以下のような記述となります。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Person",
"name": "青木 創平",
"birthDate": "1994-08-19"
}
</script>
nameやbirthDateという値が含まれているのが御覧頂けるかと思いますが、特定の情報に対してHTMLマークアップを行う(メタデータを付与する)ことでその情報の説明が付与することができるようになります。
構造化データを使用するメリット
検索エンジンがサイトコンテンツの把握を容易に行えます
上述した通り、特定のテキストあるいは画像がどういう情報なのかを指し示すことで、検索エンジンはコンテンツの内容がどういう意味を持つものか、容易に把握できるようになります。
構造化データを用いることで、前述した文章は、「私の名前は青木創平で、誕生日は1994年8月19日です」のように、情報の持つ意味がより明確に検索エンジンに伝わり、適切に認識されるようになります。
検索結果にリッチリザルトが表示されます
通常の検索結果においてサイトが表示される際には青色のリンク、その下meta descriptionやサイト内テキストから引用したスニペットが表示されますが、構造化データを用いることで、リンクの下に通常とは異なる情報が表示されることがあります。これを「リッチリザルト」と言います。
こういった検索結果を見たことがある方は多いのではないかと思います。
▼リッチリザルトの例


この場合はパンくずリスト、レビュー、価格帯の情報がマークアップされたことで、検索結果にリッチリザルトとして表示されています。
これにより検索結果で目につきやすくなり、クリックされやすくなるなどのメリットがあります。リッチリザルトに対応されているコンテンツは、上の画像のパンくずリストやレビュー情報、価格情報以外にもイベント、記事、レシピなどがあります。また、2019年1月に実装された「Googleしごと検索」は構造化データをマークアップすることで「〇〇 求人」、「〇〇 バイト」のようなクエリで、エンリッチリザルトが表示され、そこからユーザーは求人に申し込むことができるようになりました。
▼「正社員 求人」の検索結果


参考:エンリッチリザルトとは(Google検索セントラルに遷移します)
ボキャブラリーとシンタックス
構造化データを理解する上で、この2つの言葉についてきちんと理解しておく必要があります。端的に言うと、ボキャブラリーが値を表し、シンタックスはその記述方法になります。
ボキャブラリー
冒頭の例では青木創平に”name”、1994-08-19に”birthDay”という値を付けました。その指定する値を定義している規格のようなものがボキャブラリーです。
ボキャブラリーの代表的なものにschema.orgがあります。schema.orgはGoogle、yahoo!、Microsoftの大手検索エンジン企業が共同で取り組んでおり、値の数は日々拡張されています。
先ほどの例は、人物の説明でしたが、人物を説明する際には名前や誕生日はもちろんのこと、所属している団体やその人が運営するサイトなども説明することがあるかと思います。schema.orgはそういった部分も網羅しており、例えば人物(Person)であればこちらのページにてまとめられています。Propertyという欄で人物の説明に対してマークアップ可能な値が表示されています。
▼schema.orgのPersonのページ

また、見て頂くとわかるかと思いますが、プロパティは階層構造となっています。
例えば、「Thing(もの)」という大項目の子として「Book(本)」や「Event(イベント)」という項目、「Event(イベント)」の子として「BusinessEvent(企業向けイベント)」といった階層を形成しています。
シンタックス
ボキャブラリーは値を定義しているだけのものですので、HTMLにマークアップする際にはどうマークアップするかの仕様が必要ですが、その仕様がシンタックスです。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Person",
"name": "青木 創平",
"birthDate": "1994-08-19"
}
</script>
ちなみにこの文章でいうと<script type="application/ld+json">~</script>の部分がシンタックスで決められている仕様です。
シンタックスには代表的なもので以下の3つがあります。
- JSON-LD
- Microdata
- RDFa
Googleが推奨しているのはJSON-LDです。(この記事でもJSON-LDを採用しています。)
参考:構造化データの形式(Google検索セントラルに遷移します)
また、JSON-LDはHTML上で各情報に直接マークアップするその他のシンタックスとは異なり、スクリプトを用いて記述するため、各データに直接マークアップする必要がなく、HTMLのどこに記述しても大丈夫な仕様になっております。
先ほどの例で再確認
再度、青木創平の例を用いて詳しく見てみましょう。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Person",
"name": "青木 創平",
"birthDate": "1994-08-19"
}
</script>
1. <script type="application/ld+json">~</script>
JSON-LDでマークアップする際のルールとして、必ずこの記述をします。また、scriptとありますが、スクリプトを実行させるものではありません。この間にマークアップします。
2. "@context": "http://schema.org"
この記述はschema.orgを使って記述することを宣言するためのものです。
schema.orgとJSON-LDの組み合わせで記述する際は必ずこの記述をします。ここまでは基本固定で大丈夫です。
3. "@type": "Person"
@type で何について表現するのかを指定します。今回であれば、人についてはPersonで定義されています。他にも、イベントは、Eventで定義、製品などはProductで定義されています。
4. "name": "青木 創平",
@typeで指定しているバリューを表現するためにキーに値を入れていきます。今回であればバリューはPerson、キーはname、値は青木 創平となります。また、キーはバリューに紐付いております。
構造化データをマークアップする方法
構造化データを検索エンジン(Google)に伝える際には大きくわけて2つの方法があります。
- HTML上で直接マークアップする方法
- データ ハイライターを用いる方法
前者のHTMLに直接マークアップする方法は、文字通り上述した青木の例のようにHTMLタグに構造化データの要素を追加する方法になります。
一方でデータ ハイライターを用いる場合、ウェブマスターツールのページ上でクリックすることによりページの構造化データを(HTMLをいじることなく)Googleに伝えることが可能です。
Googleヘルプには以下のように書かれています。
■データ ハイライターの使用ができるケース:
記事
イベント
地域のお店やサービス
レストラン
商品
ソフトウェア アプリケーション
映画
テレビ番組のエピソード
書籍
引用元:データ ハイライターについて
どちらの方法もメリット・デメリットがありますので、運営されている体制やサイトの状況などにより、どちらを使うか検討することが望まれます。
ではそれぞれ実際に説明していきましょう。
\ここまで読んで不明点がございましたら、バナーをクリックしてご相談ください!/

構造化データをHTML上で直接マークアップする方法
この方法には大きく分けて2つあります。それぞれ説明します。
ゴリゴリっとHTMLにマークアップしていく方法
今回はボキャブラリーにschema.orgとシンタックスにJSON-LDを用いてマークアップする方法で紹介します。
一般的に構造化データがマークアップされている情報は人物や商品、パンくずが多いですが、こちらにまとめられている通り、マークアップできる情報は他にも沢山あります。
今回は以下の文章について考えてみましょう。
<div>会社名:ナイル株式会社</div> <div>住所:東京都品川区東五反田1-24-2東五反田1丁目ビル7F</div> <div>問合せ先:03-6409-6766</div> <div>創業年:2007年1月15日</div> <div>創業者:高橋飛翔</div> <div>オフィシャルサイト:https://nyle.co.jp/</div>
①まずは構造化マークアップできる箇所を確認しましょう。
構造化データをマークアップできる箇所と、マークアップすることで検索結果にリッチリザルトとして表示されるかを確認しましょう。今回はすべての情報をマークアップできますが、問い合わせ先以外はマークアップしても、検索結果にリッチリザルトが表示されません。もちろん、だからといってマークアップ自体が無駄になるわけではなく、構造化データの設定により検索エンジンは意味情報を理解しやすくなります。あくまでマークアップの優先度を考える際などに役立てましょう。
②マークアップを行いましょう。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "ナイル株式会社",
"founder": "高橋飛翔",
"foundingDate": "2007年1月15日",
"url": "https://nyle.co.jp/",
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+81-3-6409-6766",
"contactType": "customer support",
"areaServed": "JP"
},
"address": {
"@type": "PostalAddress",
"addressLocality": "品川区, 東京",
"postalCode": "141-0022",
"streetAddress": "東五反田1-24-2東五反田1丁目ビル7F"
}
} </script>
これでこのテキストに構造化データをマークアップできました。
※ページ数が極端に少ない場合を除き、CMSにプラグイン導入したり、DBサイトなどはシステムで構造化データを付与したりすることになるはずです。開発担当に聞いてみてください。
構造化データマークアップ支援ツールを用いた方法
ウェブマスターツールには、構造化データマークアップを支援する機能があります。
先に説明した方法だとschema.orgなどを理解した上でマークアップする必要がありましたが、こちらの方法はそれよりも容易に構造化データを用いることが可能になります。
ここでは弊社平塚が執筆したブログを用いて説明します。
①構造化データマークアップ支援ツールに該当するページのURLを入力し、今回マークアップするデータを選択した上でタグ付け開始をクリックします。
▼ページタイプとURLの入力ページ
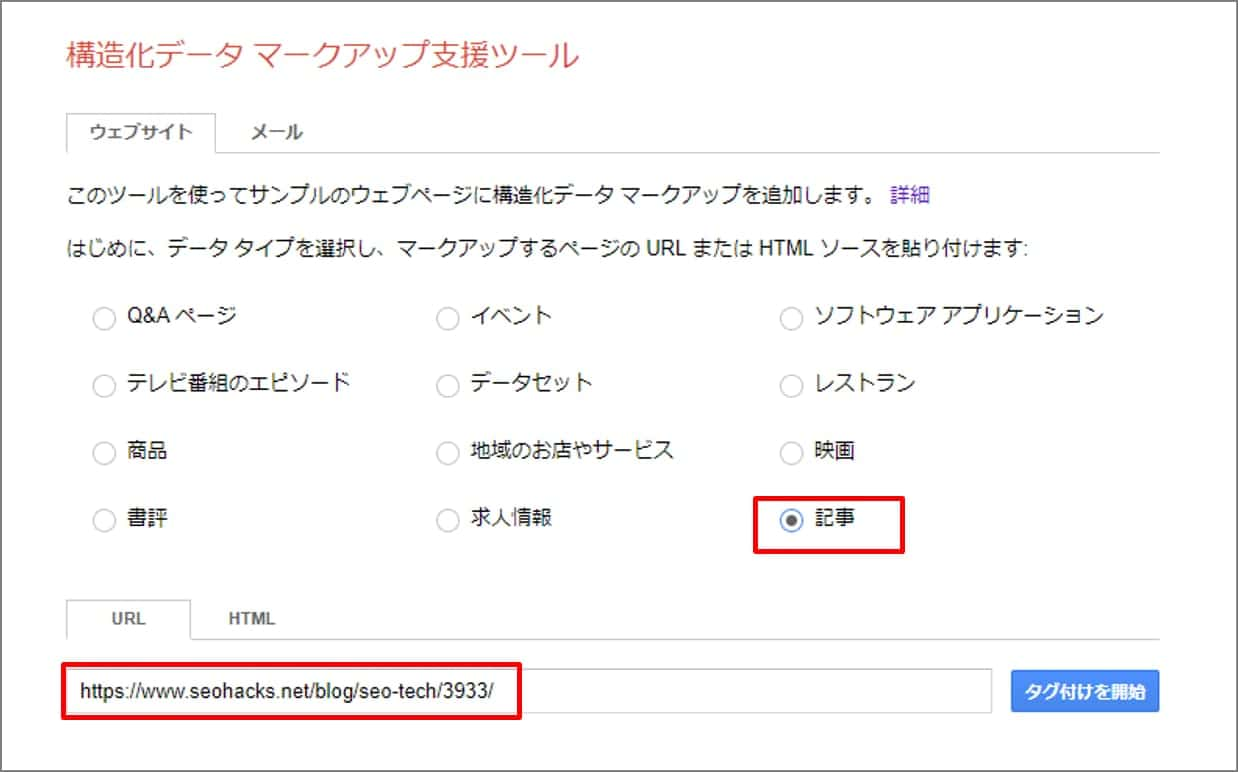
今回はブログ記事のマークアップですので、記事を選択しました。
②実際にマークアップしてみましょう。
タグ付けはツール内でページが読み込まれた画面で行います。右にタグ付けできるデータが並びます。この例で言うと、前の画面で記事を選んだため、著者や公開日など、記事に関連するデータが並んでいます。
ではまず一番上にある「名前」(今回の場合は記事タイトルです)をマークアップしてみましょう。
▼データのタグ付けページ
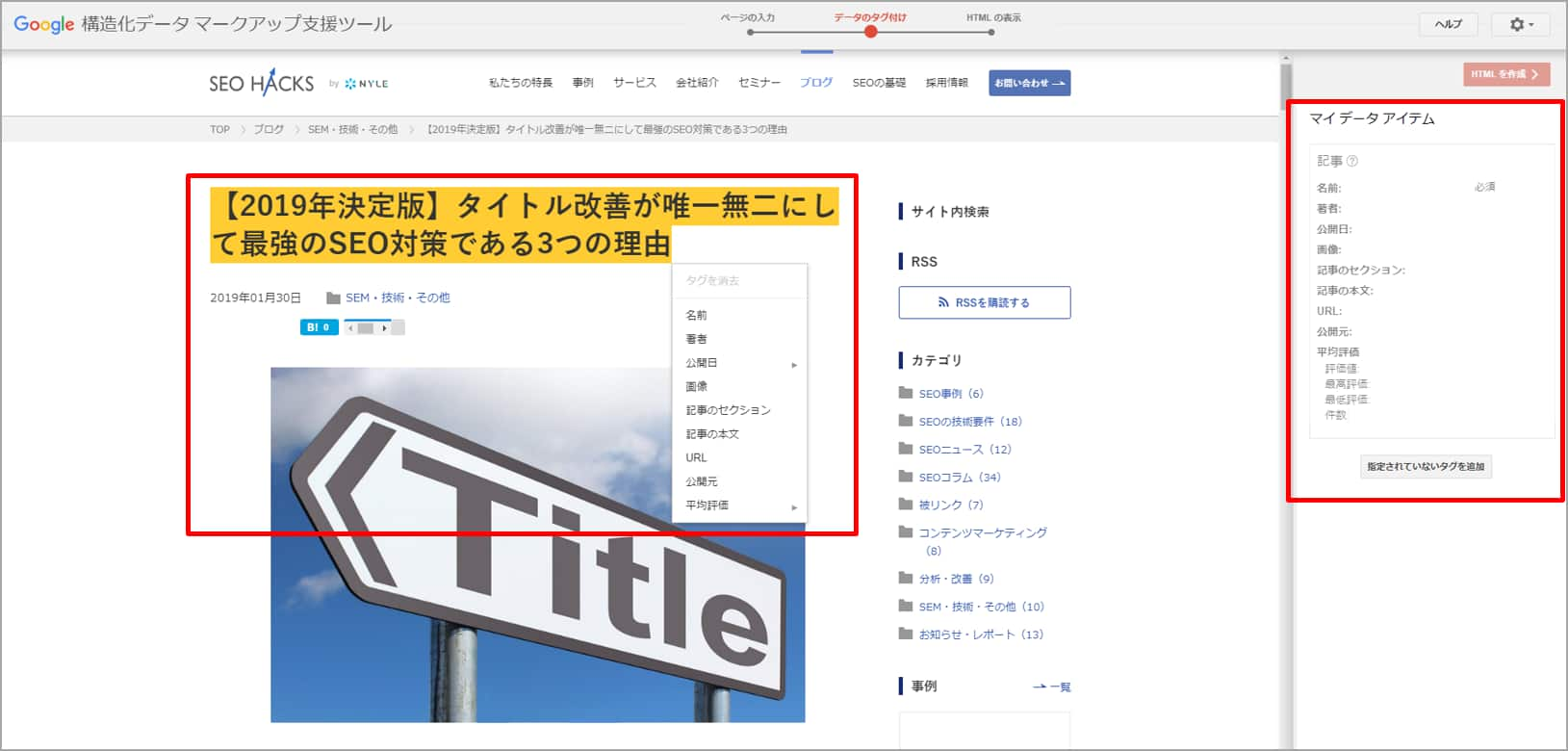
タイトルに当たるところをドラッグすると、選択肢が出てきますのでそこから「名前」を選択しますと右側にマークアップしたいテキストもしくは画像が追加されます。著者情報や公開日なども 同様の要領で指定していきます。
データの指定が終わったら右上にある「HTMLを作成」をクリックするとそのページのHTMLが出力されます。
▼出力されたHTML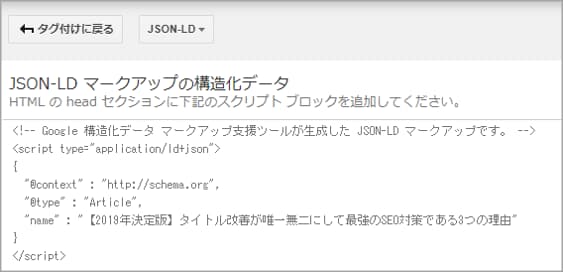
③出力されたHTMLをサイトに反映させます。
サイト運用の仕方にもよりますが、出力されたHTMLをコピーしてHTMLを実装しましょう。これでマークアップは完了です。制限は多いですが、専門的な知識がなくても構造化データをマークアップできるのがメリットですね。自分のサイトにはどのような構造化データをマークアップできるのか確認するのにも役立ちます。
データ ハイライターを用いる方法
データ ハイライターを用いた場合には 直接HTMLをいじる必要がなく、構造化データマークアップ支援ツールのようにブラウザ上でクリックすることで構造化データをGoogleに伝えることが可能です。
①ウェブマスターツールでデータハイライターを開きます。
ハイライト表示を開始しましょう。
▼URLとページタイプの選択画面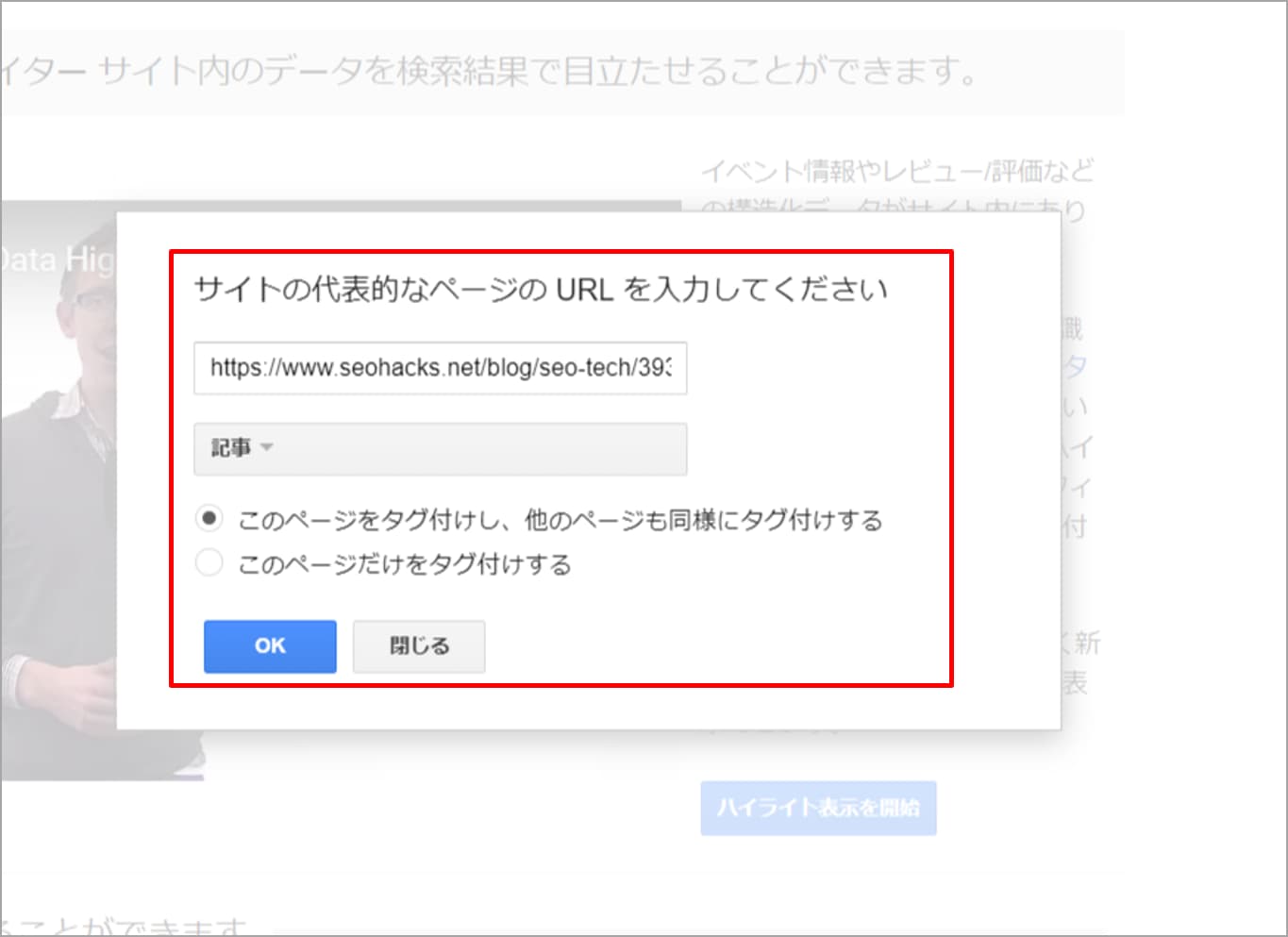
先ほどと同様に構造化データを設定したいURLを入力し、タイプを選択します。今回も弊社平塚が執筆したブログを用いますので、タイプに「記事」を選択しました。
また「このページをタグ付けし、他のページも同様にタグ付けする」の場合は(幾つかのサンプルページにてタグ付けを行うことで)同様のページ群もGoogleが学習して構造化データを認識してくれるようになります。一方で「このページだけをタグ付けする」場合はGoogleに学習させず選択したページのみをタグ付けしたい場合に用います。
ブログ記事のように同じようなページ群がある場合には前者、そうでない場合には後者が望まれると思います。
今回はブログ記事ですので前者を選択しました。
②タグ付けを行います。
▼タグ付け画面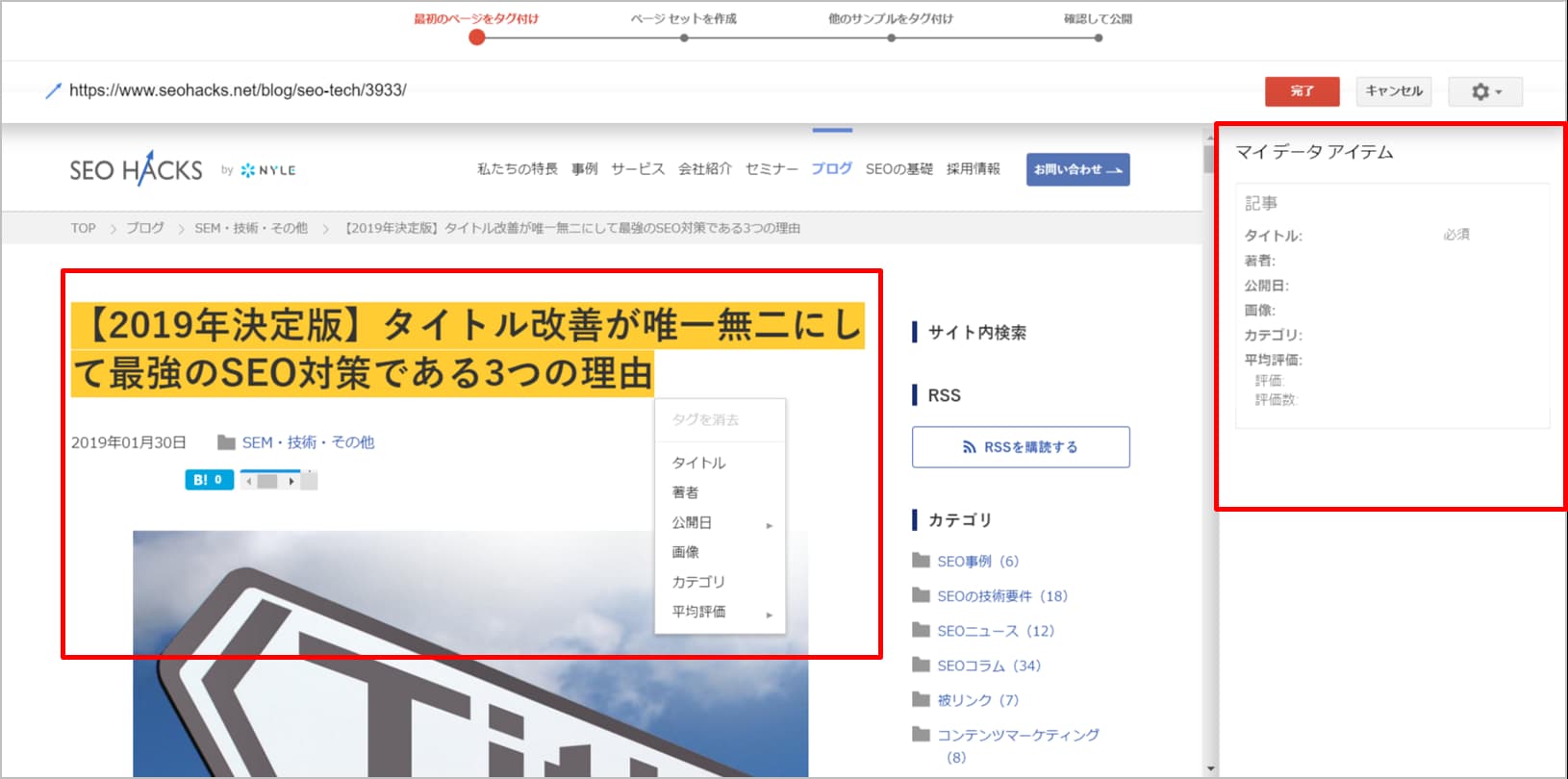
上述した構造化データマークアップ支援ツールと同様に、タグ付けしたいところをクリックもしくはドラッグし、タグ付けするデータを選択します。タグ付けが終了したら右上の「完了」を選択しましょう。
③Googleに自動でタグ付けして欲しいページを選択します。
※この選択肢は「このページをタグ付けし、他のページも同様にタグ付けする」を選択した場合にのみ表示されます。
▼ページセットの作成画面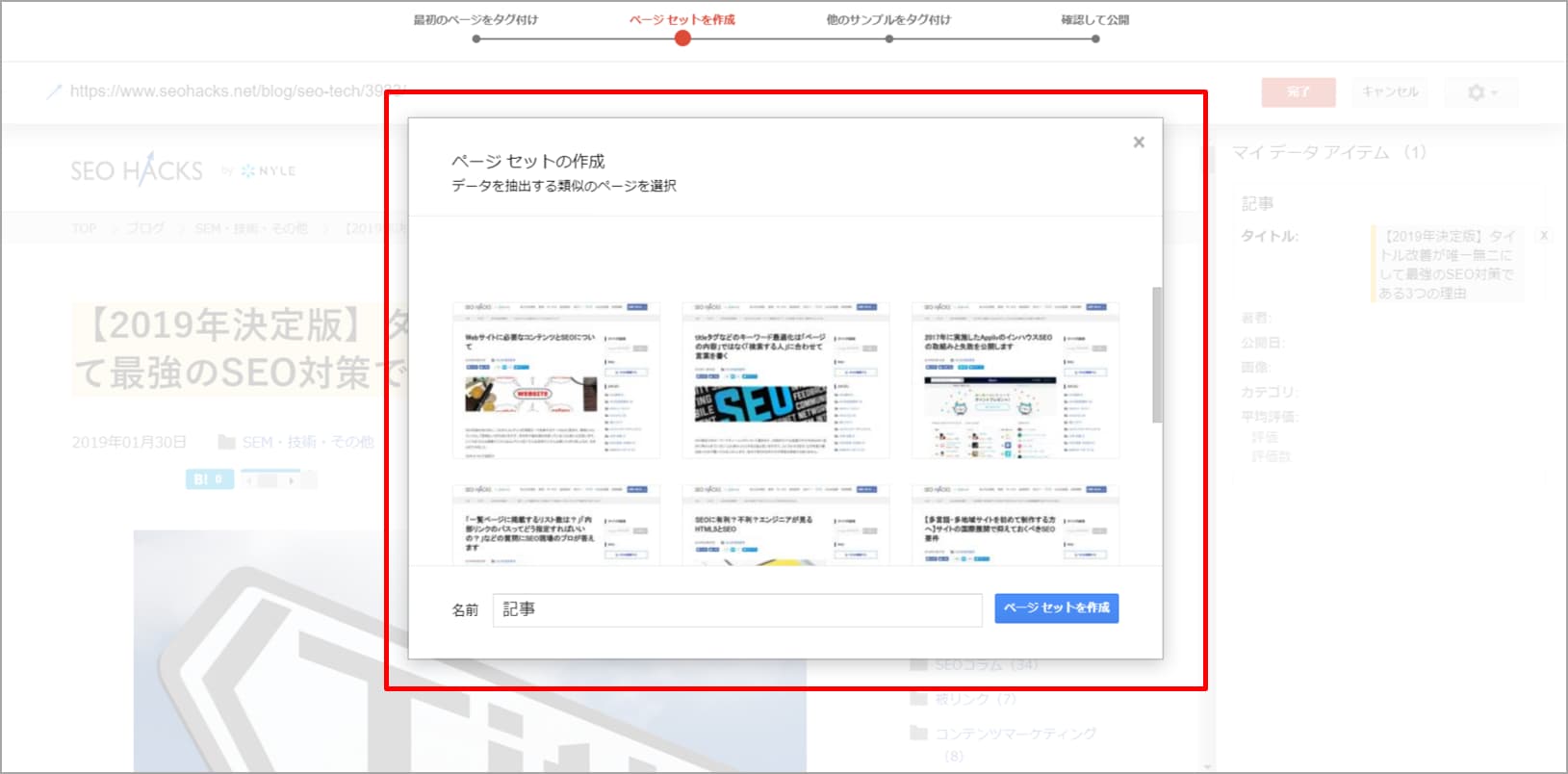
Googleが同様のタイプだと判断したページ群が選択肢として表示されます。それでは問題がある場合は「カスタム」で設定しましょう。※ページ群の設定は正規表現で行います。
これらを選択したら「ページセットを作成」に進みましょう。
④サンプルページで上手く設定できているか確認します。
Googleは最初にタグ付けした設定から他のページでも同様の構造化データをタグ付けします。このページでは③で選択した構造化データを設定したいページ群の中から、構造化データ部分をハイライトした状態でサンプルページが表示されます。自分の意図通りに設定されている場合には、右上の「次へ」をクリックしましょう。
▼サンプルページの確認画面1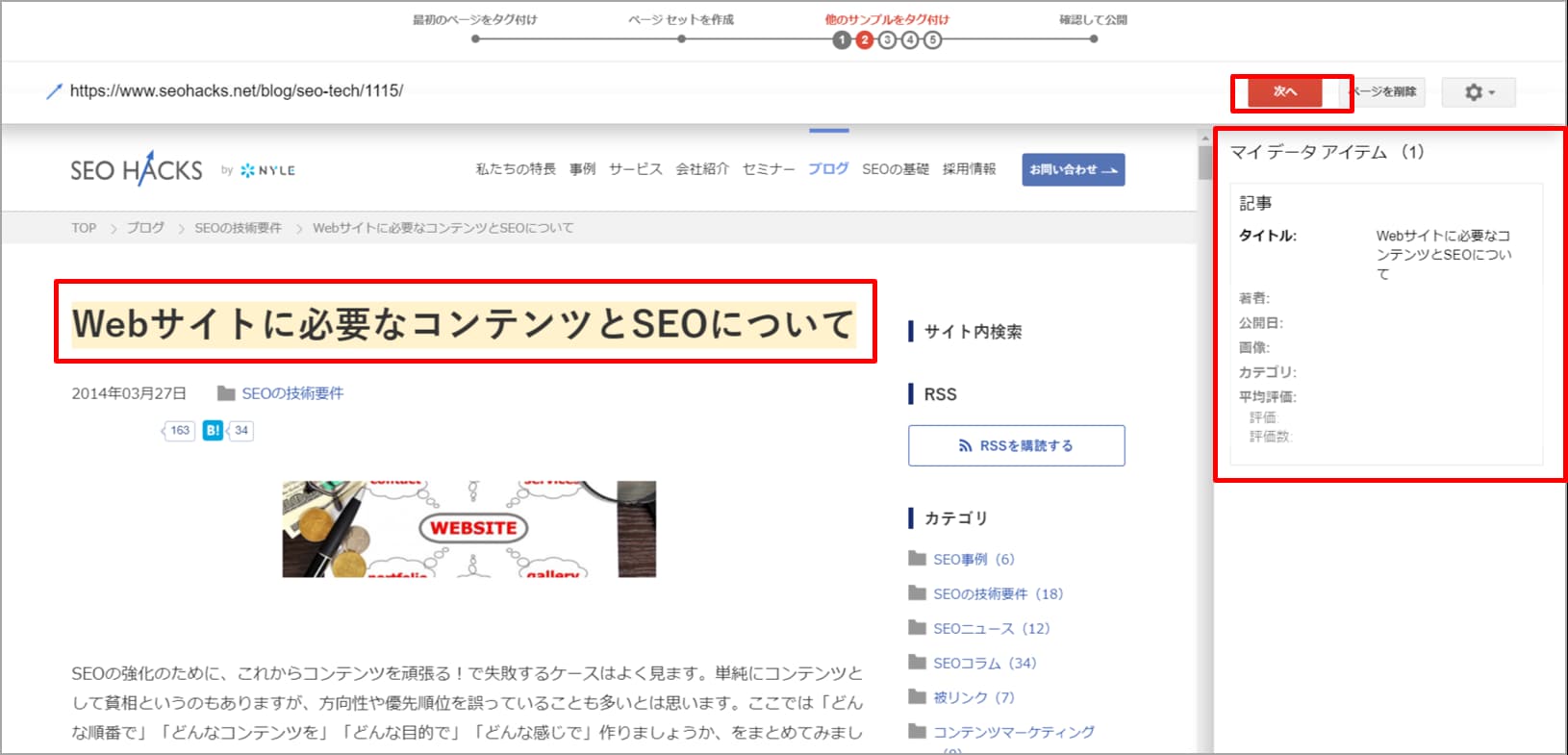
次々にサンプルが表示されますので、問題がある場合には手動で設定を修正しましょう。5ページ分のサンプルを確認すると、「完了」という項目が右上に表示されるので次に進みましょう。
▼サンプルページの確認画面2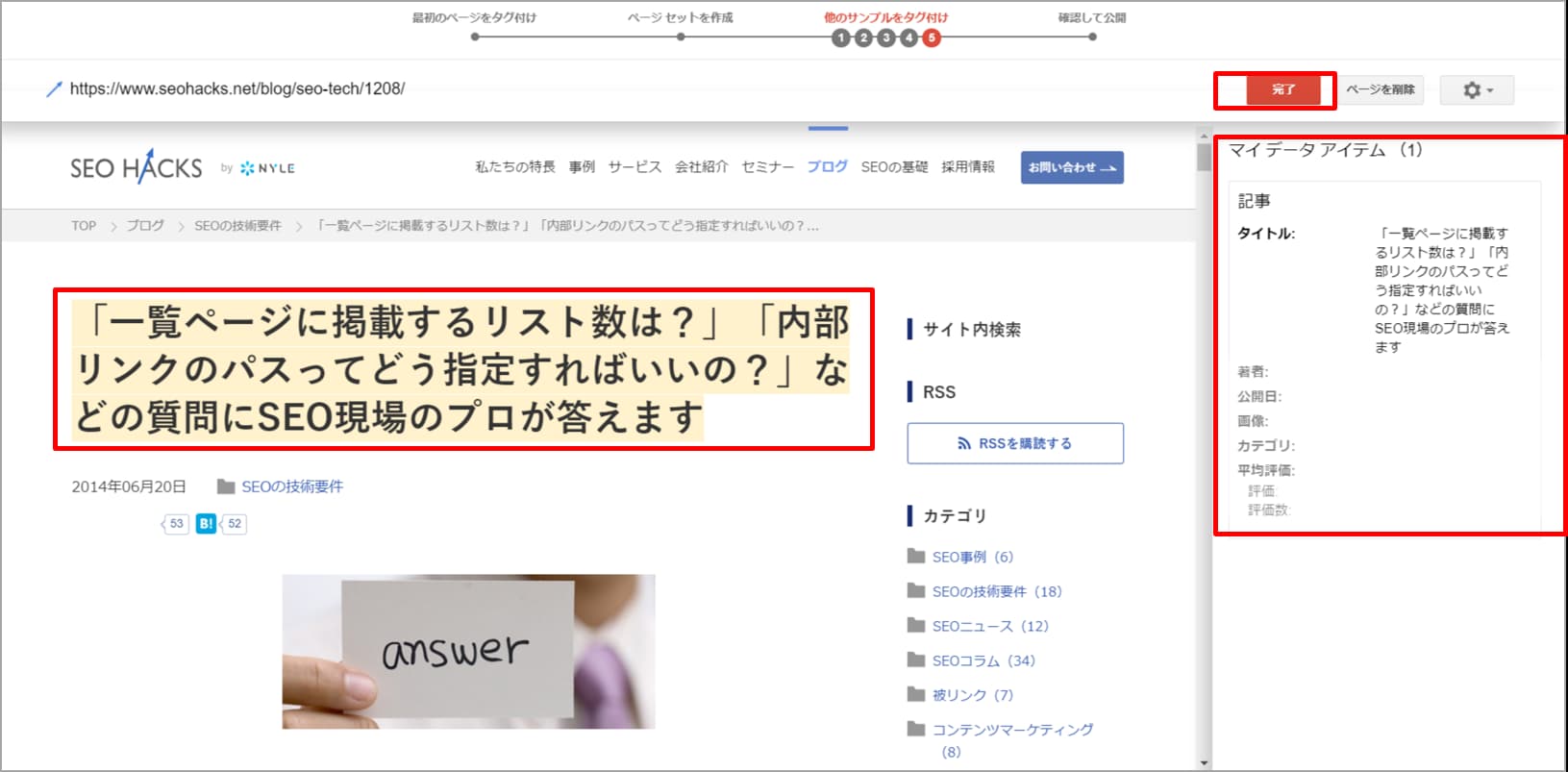
最後に確認したサンプルページを再度見直して、問題が無い場合は右上の「公開」ボタンを押しましょう。これでデータハイライターによる構造化データの設定は完了です。
\SEO対策をもっと知りたい方は要チェック/
テストツールのご紹介
構造化マークアップのテストツールについてご紹介します。
構造化データ テスト ツール
構造化データ テスト ツールで正しく構造化データが記述できているかを確認できます。下記のリッチリザルトテストはリッチリザルト対応構造化データのみですが、こちらは付与される構造化データすべてを確認することができます。用途に合わせて使い分けましょう。
構造化データのマークアップを行った後には出来る限りこのツールを用いて、正しく設定されたかを確認するようにしましょう。
リッチリザルトテスト
リッチリザルトテストではURLもしくはHTMLを入力することでそのページに設定した構造化データが正しく設定されているか、どの項目が設定されているかに加えて、検索結果上でどういう表示がされるページなのかを確認できます。
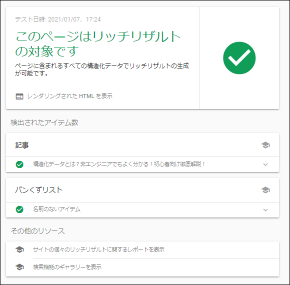
構造化データのマークアップを行った後には出来る限りこのツールを用いて、正しく設定されたかを確認するようにしましょう。
Google Search Consoleの「構造化データ」項目
Google Search Consoleの構造化データでは、構造化データの設定にエラーが無いか一覧で確認することができます。検索結果のプレビュー機能は無いですが、構造化データにエラーがあるデータタイプやページが一覧で確認できますので、URLを何度も入力する必要のある構造化データテストツールよりもその点は便利です。サポートしている(確認できる)構造化データはリッチリザルトのステータス レポート - Search Console ヘルプを確認してください。
まとめ
ここ最近のGoogleの動きを見ても、構造化データを利用する重要性は言わずもがなだと思います。ECサイトなどは受ける恩恵も大きく、サイトによってはもはや必須と言っても良いかもしれません。しかし、リッチリザルトが表示されない構造化データのマークアップに関しては、コスト・工数的に現実的でない場合が多く、そのあたりのバランスはなかなか難しいです。サイトの施策状況やリソースから考えると良いでしょう。
もし構造化データを含めたSEOのことでご相談があれば、ナイルのSEOコンサルティングのページよりお気軽にご連絡ください。
集客・コンバージョン数を増やしたい方へ

参考
- 構造化データの仕組みについて | 検索 | Google Developers
- Googleがサポートする構造化データ
- schema.org公式サイト
- [構造化データ初級者向け] schema.orgとMicrodata、RDFaって何が違うの?
- セマンティックSEOと構造化データのマークアップに関する5つの疑問に答える(前編)
- セマンティックSEOと構造化データのマークアップに関する5つの疑問に答える(後編)
ナイル株式会社 青木





PIVOTにもスポンサード出演しました!

動画内では、マーケティング組織立ち上げのための新しい手段についてお話しています。
マーケティング組織に課題がある方はぜひご覧下さい。
動画を見る












